The AWS Health Dashboard can't be trusted
I’m the co-founder of EmailOctopus, an email marketing platform with a slight difference. Users can connect our platform to their AWS account and send emails through Amazon’s Simple Email Service (SES). Amazon are really good at delivering emails reliably and cheaply, which means our average user pays 20% of the price of our biggest competitor, Mailchimp.
Amazon SES also provides metrics on how emails perform. It’s this data that powers our reporting features:
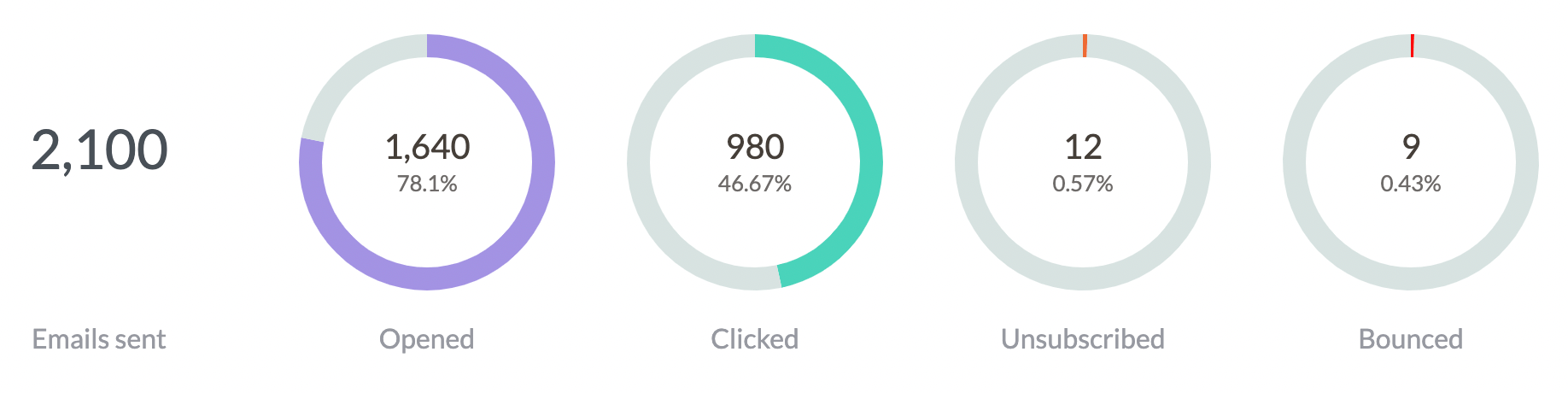
Thousands of our users rely on these reports every day. So when they stopped working last Thursday our support channels started getting busy:



We quickly determined that we were receiving fewer click and open events from SES than usual. In fact we were receiving none at all in the us-east-1 and us-west-2 regions. Our users’ reports were a tumbleweed of activity:
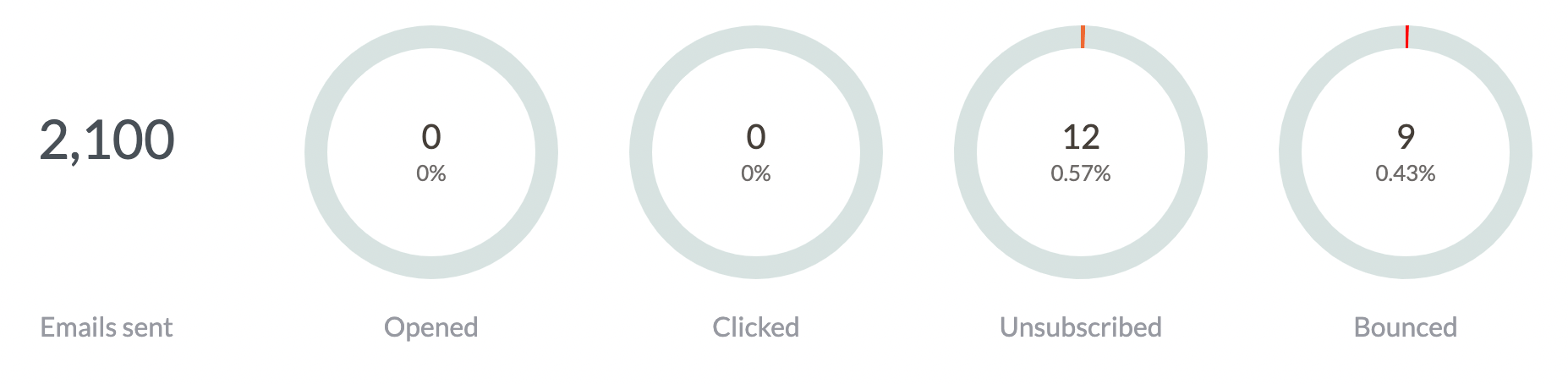
And our internal metrics weren’t looking much better – events dropped off a cliff around 12pm UTC:

We were still receiving other event types, but opens and clicks make up the bulk of our activity.
This is where things got frustrating. We fired off a message to Amazon’s premium support team on the off chance this could be an SES issue – but with ten hours having passed and nothing on the AWS health dashboard – we assumed it had to be an issue with our systems. All of our developers were online trying to figure this out, when all of a sudden events started coming through again:

And while events continued to come in correctly, we continued to debug and monitor things on our end – just in case it was our fault. Until almost four days later, when Amazon confirmed they had an outage totalling over 12 hours across two regions:
Between 10:00 AM and 10:55 PM [UTC] in the [us-east-1] region, and between 12:50 PM and 10:45 PM [UTC] in the [us-west-2] region we experienced an issue processing Opens & Clicks data. The notification events could not be saved during this period and events could not be reprocessed. The issue has been resolved and the service is operating normally.
To be clear, every single click and open event that occurred in those regions over the course of 12 hours had been permanently lost. This has had a huge impact on our customers – and the fact we couldn’t tell them what had happened for almost four days didn’t make things any easier. We asked Amazon why this wasn’t noted in the Health Dashboard:
This class of issues are identified to go to customers Personal Health Dashboard, However due to issues with our instrumentation this wasn’t possible.
This feels strikingly similar to the S3 outage in 2017, when the dashboard embarrassingly showed green ticks for the entirety of the two hour outage because the dashboard relied on… S3.
Almost five years on and the Health Dashboard still can’t be trusted to accurately report on the status of a service. And at the time of this blog post – seven days after this 12 hour outage – this update still hasn’t been posted to the AWS health dashboard. Nothing to see but green ticks: